We unify self-motion and object motion as one-parameter Lie flows and enforce flow equivariance to learn stable latent world representations that generalize to long rollouts in partially observed environments.
We extend equivariant network theory to flows – time-parameterized Lie symmetries such as motion – yielding RNNs that train faster and generalize across sequence lengths and velocities.
We build a score-based generative model on periodic domains by using stochastic Kuramoto synchronization as structured forward diffusion for orientation-rich images.
We introduce AUSSM, an adaptive, input-dependent unitary SSM with skew-symmetric recurrence – closing the gap between formal expressivity and scalable long-sequence training.
Conditioning on group elements factorizes symmetry learning into low-dimensional function generalization, yielding dramatic improvements on held-out symmetries.
Layer–layer similarity matrices across diverse Vision Transformers reveal block structure. We propose the Block-Recurrent Hypothesis: trained ViTs can be rewritten using only k ≪ L distinct blocks applied recurrently, enabling a program of dynamical interpretability.
We “peek inside” a neural foundation model like a physiologist – mapping temporal response properties, encoding/decoding manifolds, and introducing a tubularity metric to assess biological plausibility.
We give an analytically solvable wavelet-basis parameterization of diffusion scores in terms of data moments, offering an architecture-agnostic view of what matters for denoising.
We show how learned traveling-wave recurrent dynamics can integrate global spatial context over time, yielding strong performance on tasks like semantic segmentation with fewer parameters than non-local baselines.
We introduce learned homomorphisms as a way to generalize the benefits of equivariant learning to broader, data-driven structure—bridging disentanglement, equivariance, and topographic organization.
 We unify self-motion and object motion as one-parameter Lie flows and enforce flow equivariance to learn stable latent world representations that generalize to long rollouts in partially observed environments.
We unify self-motion and object motion as one-parameter Lie flows and enforce flow equivariance to learn stable latent world representations that generalize to long rollouts in partially observed environments. We extend equivariant network theory to flows – time-parameterized Lie symmetries such as motion – yielding RNNs that train faster and generalize across sequence lengths and velocities.
We extend equivariant network theory to flows – time-parameterized Lie symmetries such as motion – yielding RNNs that train faster and generalize across sequence lengths and velocities. We build a score-based generative model on periodic domains by using stochastic Kuramoto synchronization as structured forward diffusion for orientation-rich images.
We build a score-based generative model on periodic domains by using stochastic Kuramoto synchronization as structured forward diffusion for orientation-rich images.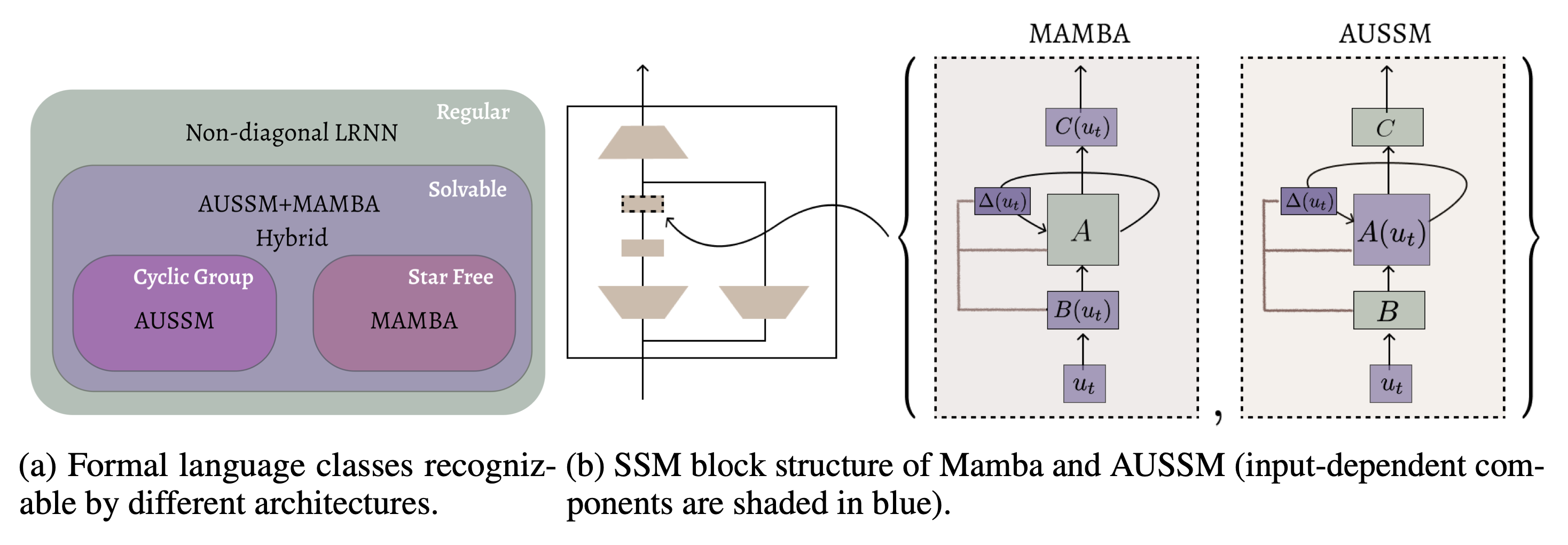 We introduce AUSSM, an adaptive, input-dependent unitary SSM with skew-symmetric recurrence – closing the gap between formal expressivity and scalable long-sequence training.
We introduce AUSSM, an adaptive, input-dependent unitary SSM with skew-symmetric recurrence – closing the gap between formal expressivity and scalable long-sequence training.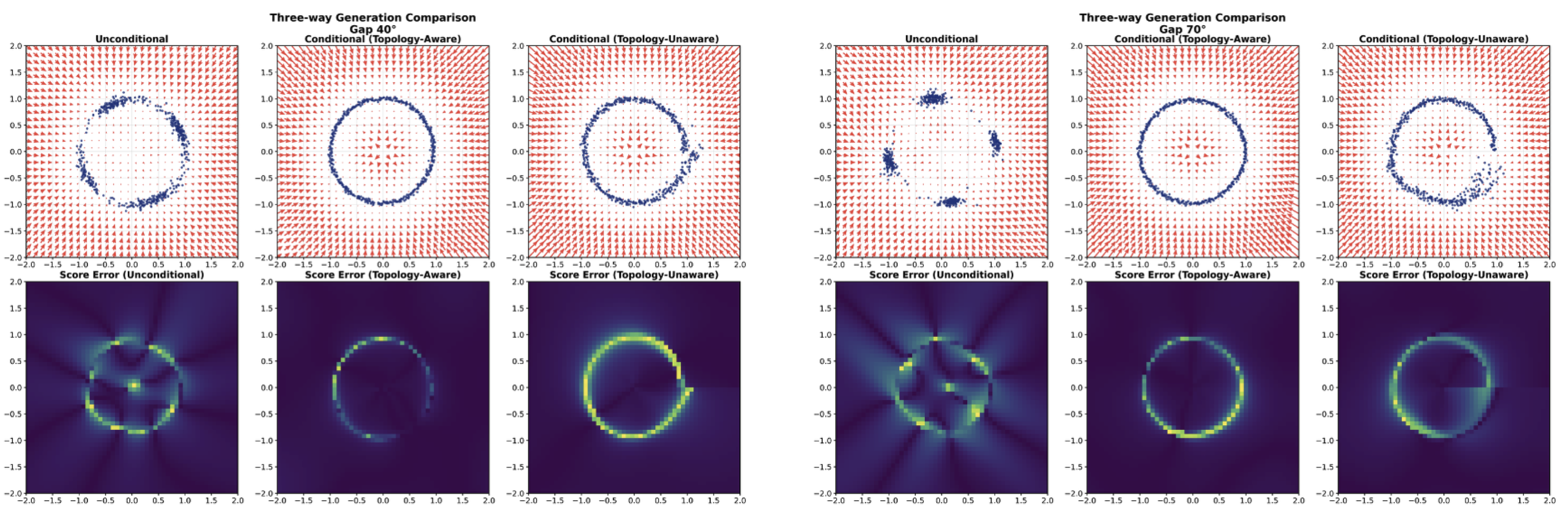 Conditioning on group elements factorizes symmetry learning into low-dimensional function generalization, yielding dramatic improvements on held-out symmetries.
Conditioning on group elements factorizes symmetry learning into low-dimensional function generalization, yielding dramatic improvements on held-out symmetries.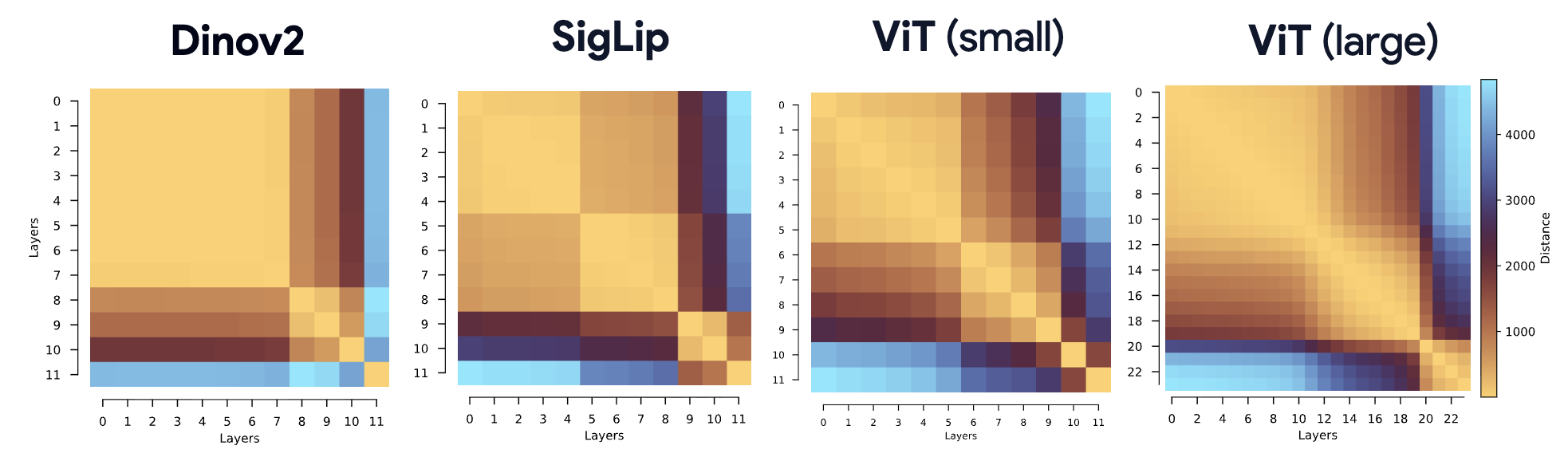 Layer–layer similarity matrices across diverse Vision Transformers reveal block structure. We propose the Block-Recurrent Hypothesis: trained ViTs can be rewritten using only k ≪ L distinct blocks applied recurrently, enabling a program of dynamical interpretability.
Layer–layer similarity matrices across diverse Vision Transformers reveal block structure. We propose the Block-Recurrent Hypothesis: trained ViTs can be rewritten using only k ≪ L distinct blocks applied recurrently, enabling a program of dynamical interpretability.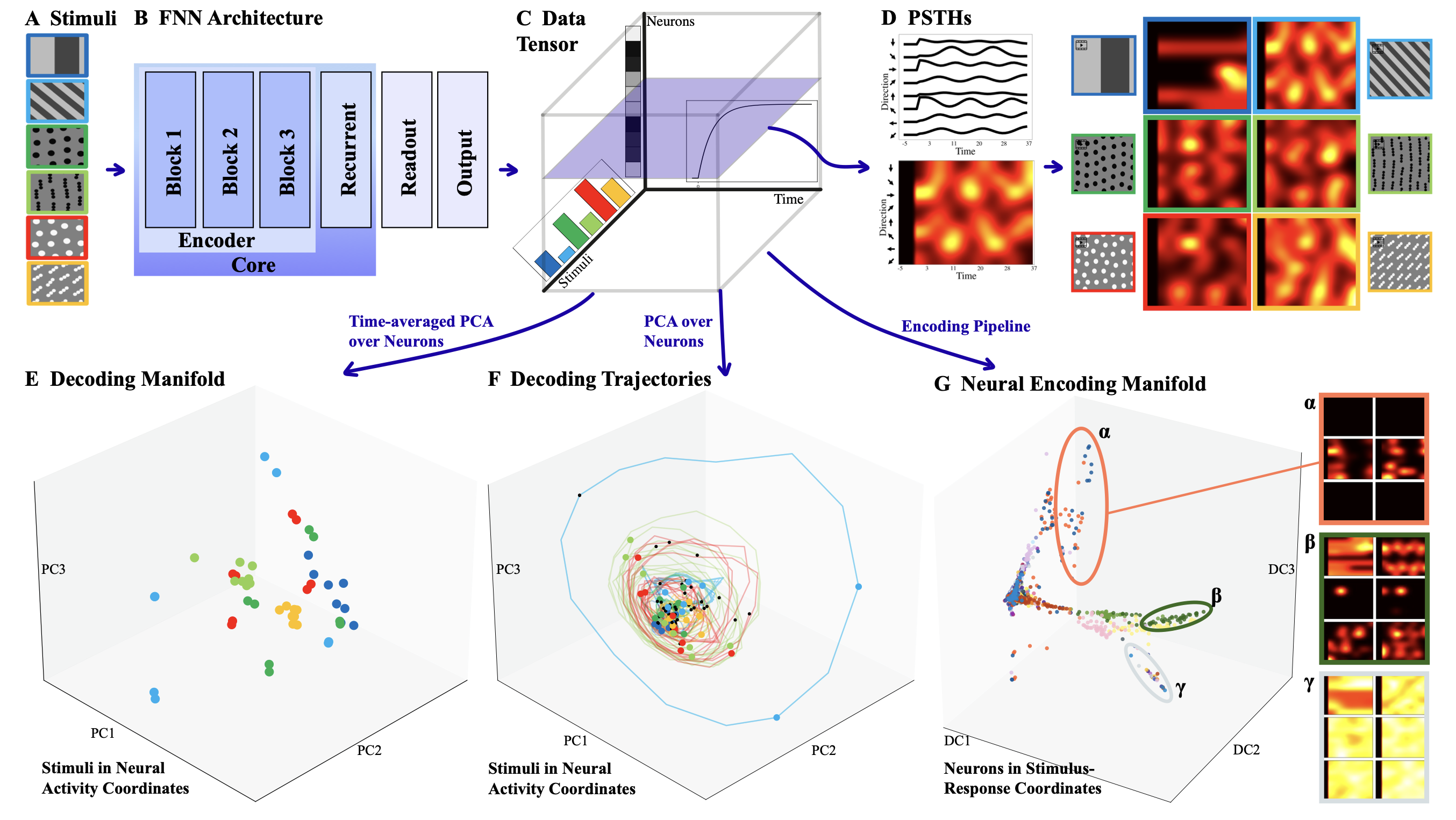 We “peek inside” a neural foundation model like a physiologist – mapping temporal response properties, encoding/decoding manifolds, and introducing a tubularity metric to assess biological plausibility.
We “peek inside” a neural foundation model like a physiologist – mapping temporal response properties, encoding/decoding manifolds, and introducing a tubularity metric to assess biological plausibility. We give an analytically solvable wavelet-basis parameterization of diffusion scores in terms of data moments, offering an architecture-agnostic view of what matters for denoising.
We give an analytically solvable wavelet-basis parameterization of diffusion scores in terms of data moments, offering an architecture-agnostic view of what matters for denoising.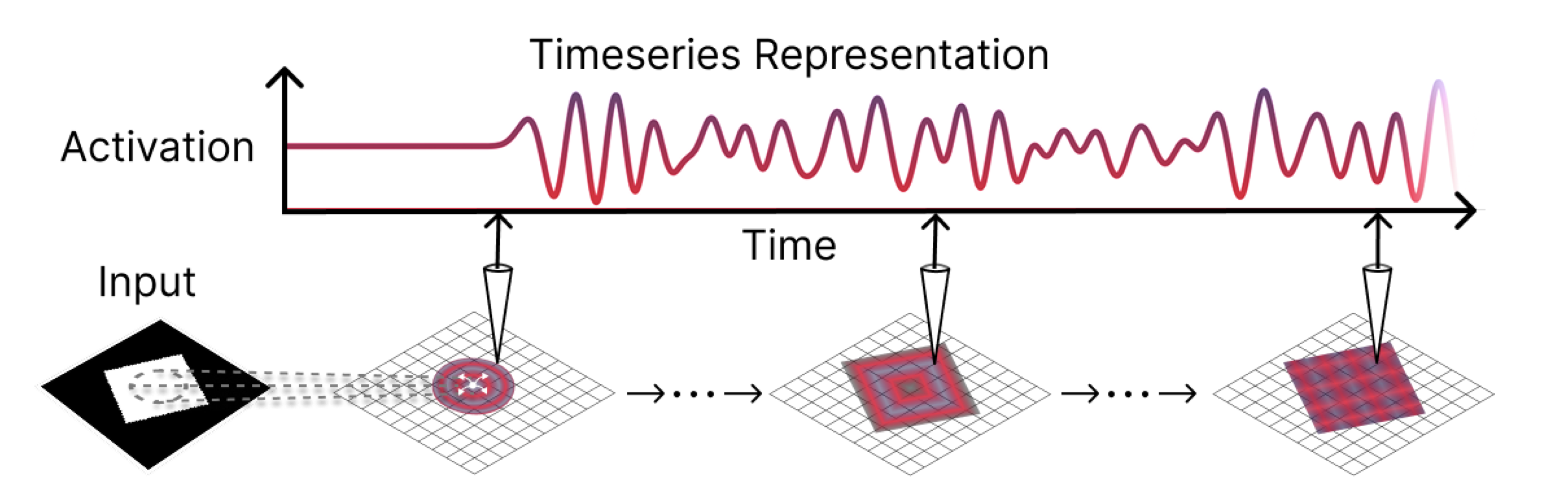 We show how learned traveling-wave recurrent dynamics can integrate global spatial context over time, yielding strong performance on tasks like semantic segmentation with fewer parameters than non-local baselines.
We show how learned traveling-wave recurrent dynamics can integrate global spatial context over time, yielding strong performance on tasks like semantic segmentation with fewer parameters than non-local baselines. We introduce learned homomorphisms as a way to generalize the benefits of equivariant learning to broader, data-driven structure—bridging disentanglement, equivariance, and topographic organization.
We introduce learned homomorphisms as a way to generalize the benefits of equivariant learning to broader, data-driven structure—bridging disentanglement, equivariance, and topographic organization.