We introduce LangevinFlow, a sequential VAE whose latent dynamics follow an underdamped Langevin equation, combining physics-inspired priors with strong performance on neural population modeling benchmarks.
We extend theory on “creativity” in convolutional diffusion models to the attention setting, predicting that attention promotes global self-consistency beyond patch-level mosaics.
Visualization of traveling waves found in the original Mamba architecture (left) and the variable velocity traveling waves we introduce in the Nu-Wave Mamba model (left). We see the variable velocity model learns exponentially faster and reaches lower error than the original counterpart.
Visualization of the phases of a network of locally coupled kuramoto oscillatos, driven by an input image (left), which converge in phase to segment the image into different shapes, with different oscillatory dynamics for each shape.
We propose a definition of artistic style that combines local texture with global symmetries and show that learned symmetries help predict movements and quantify stylistic similarity across artists.
A flow equivariant neural network will process a moving stimulus sequence the same way as it processes a static stimulus sequence, but with the same motion applied to its hidden state. To achieve this property for a specific input flow $\psi^{(\nu)}$, a corresponding flow must preemptively shift the hidden state before the input comes in (denoted by red arrows).
We learn representations from sequence data by factorizing latent transformations into sparse flow components, yielding disentangled transformation primitives and approximately equivariant structure.
Relative Representations are a method for mapping points (such as the green circle) from a high dimensional space (left) to a lower dimensional space (right), by represeniting it in a new coordinate system relative to a select set of anchor points (red and blue star). In this work we apply such an idea of relative representations to model-brain mappings and show that it improves interpretability and computational efficiency – surprisingly model-brain RSA scores are roughly consistent even with as few as 10 randomly selected anchor points (10 dimensions) compared to the original 1000’s of dimensions.
Illustration of three input signals (top) and a corresponding wave-field with induced traveling waves (bottom). From an instantaneous snapshot of the wave-field at each timestep we are able decode both the time of onset and input channel of each input spike. Furthermore, subsequent spikes in the same channel do not overwrite one-another.
My PhD Thesis, studying the inductive biases that enable the efficiency and generalization capability of natural intelligence, yet unmatched by artificial intelligence.
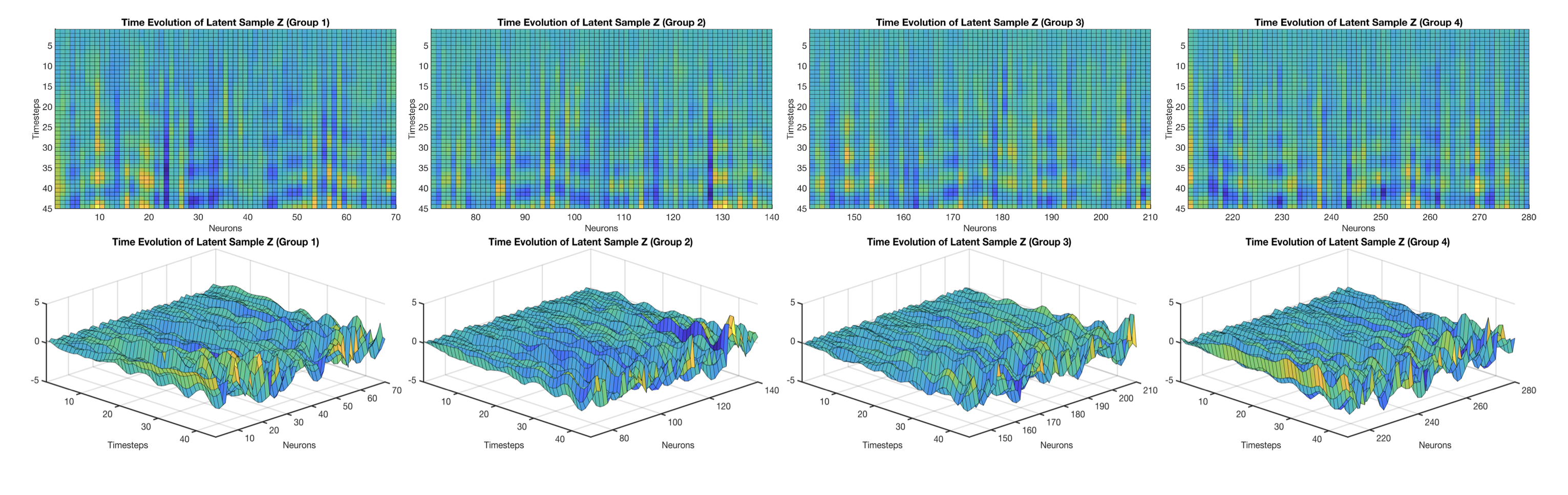 We introduce LangevinFlow, a sequential VAE whose latent dynamics follow an underdamped Langevin equation, combining physics-inspired priors with strong performance on neural population modeling benchmarks.
We introduce LangevinFlow, a sequential VAE whose latent dynamics follow an underdamped Langevin equation, combining physics-inspired priors with strong performance on neural population modeling benchmarks.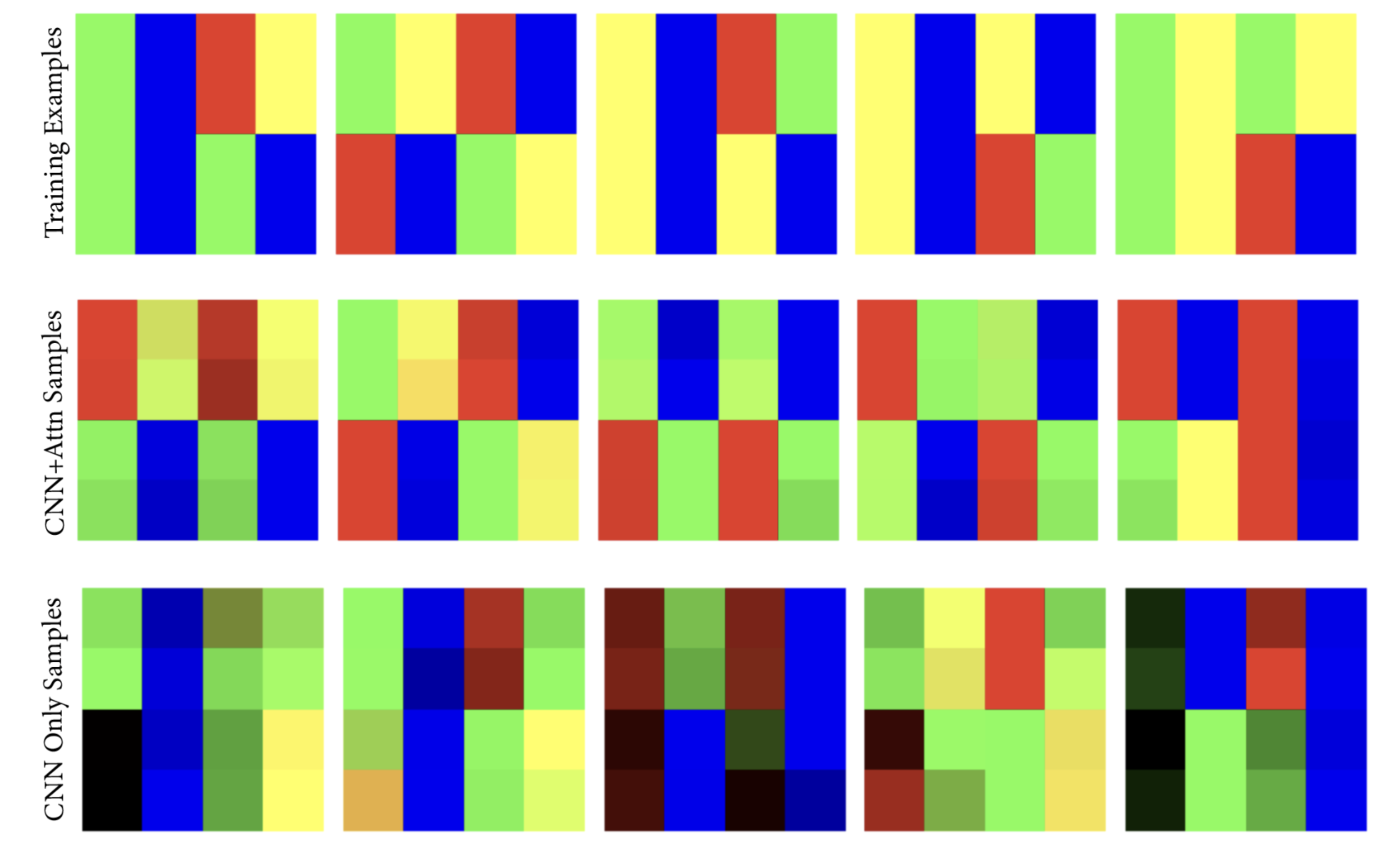 We extend theory on “creativity” in convolutional diffusion models to the attention setting, predicting that attention promotes global self-consistency beyond patch-level mosaics.
We extend theory on “creativity” in convolutional diffusion models to the attention setting, predicting that attention promotes global self-consistency beyond patch-level mosaics.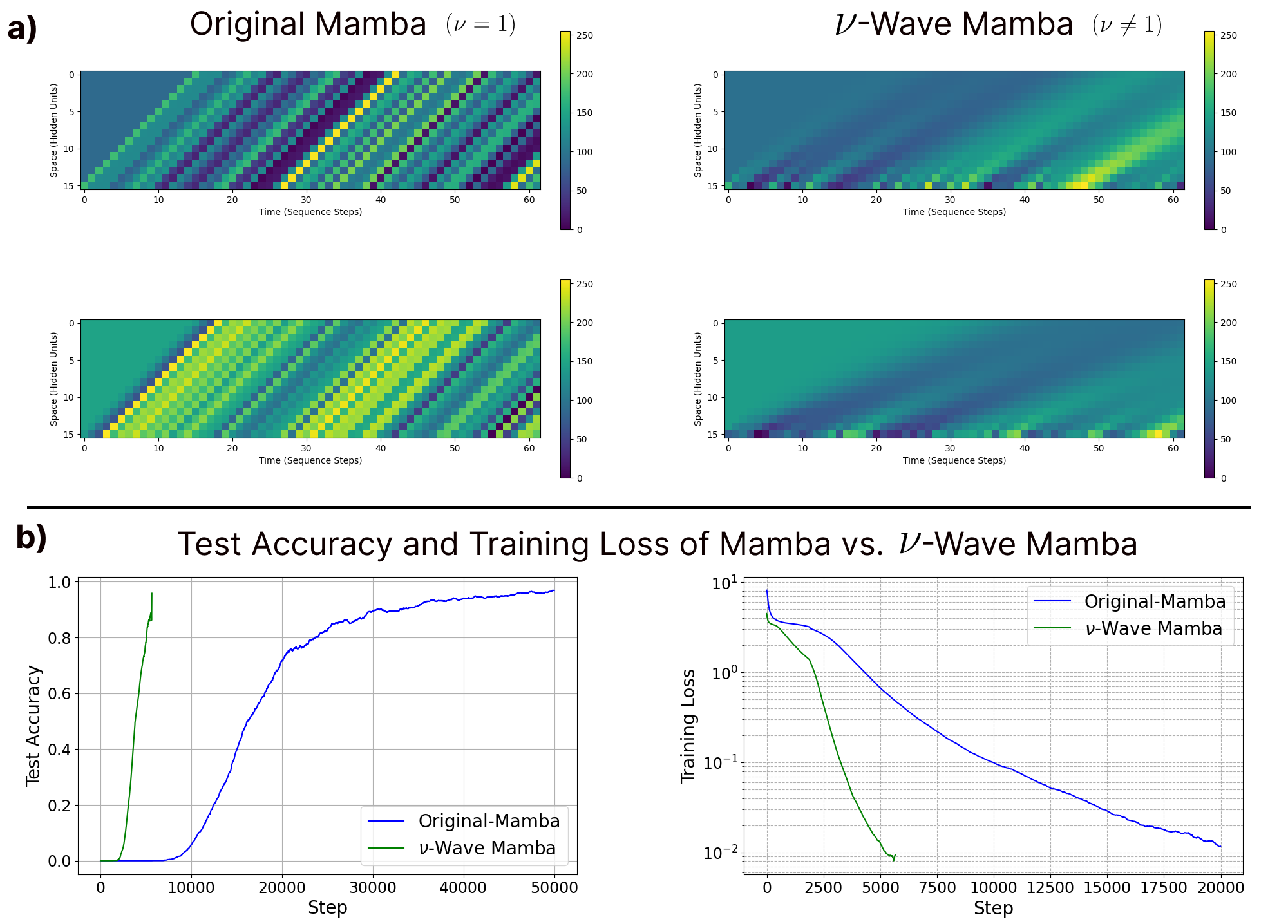 Visualization of traveling waves found in the original Mamba architecture (left) and the variable velocity traveling waves we introduce in the Nu-Wave Mamba model (left). We see the variable velocity model learns exponentially faster and reaches lower error than the original counterpart.
Visualization of traveling waves found in the original Mamba architecture (left) and the variable velocity traveling waves we introduce in the Nu-Wave Mamba model (left). We see the variable velocity model learns exponentially faster and reaches lower error than the original counterpart. Visualization of the phases of a network of locally coupled kuramoto oscillatos, driven by an input image (left), which converge in phase to segment the image into different shapes, with different oscillatory dynamics for each shape.
Visualization of the phases of a network of locally coupled kuramoto oscillatos, driven by an input image (left), which converge in phase to segment the image into different shapes, with different oscillatory dynamics for each shape. We propose a definition of artistic style that combines local texture with global symmetries and show that learned symmetries help predict movements and quantify stylistic similarity across artists.
We propose a definition of artistic style that combines local texture with global symmetries and show that learned symmetries help predict movements and quantify stylistic similarity across artists.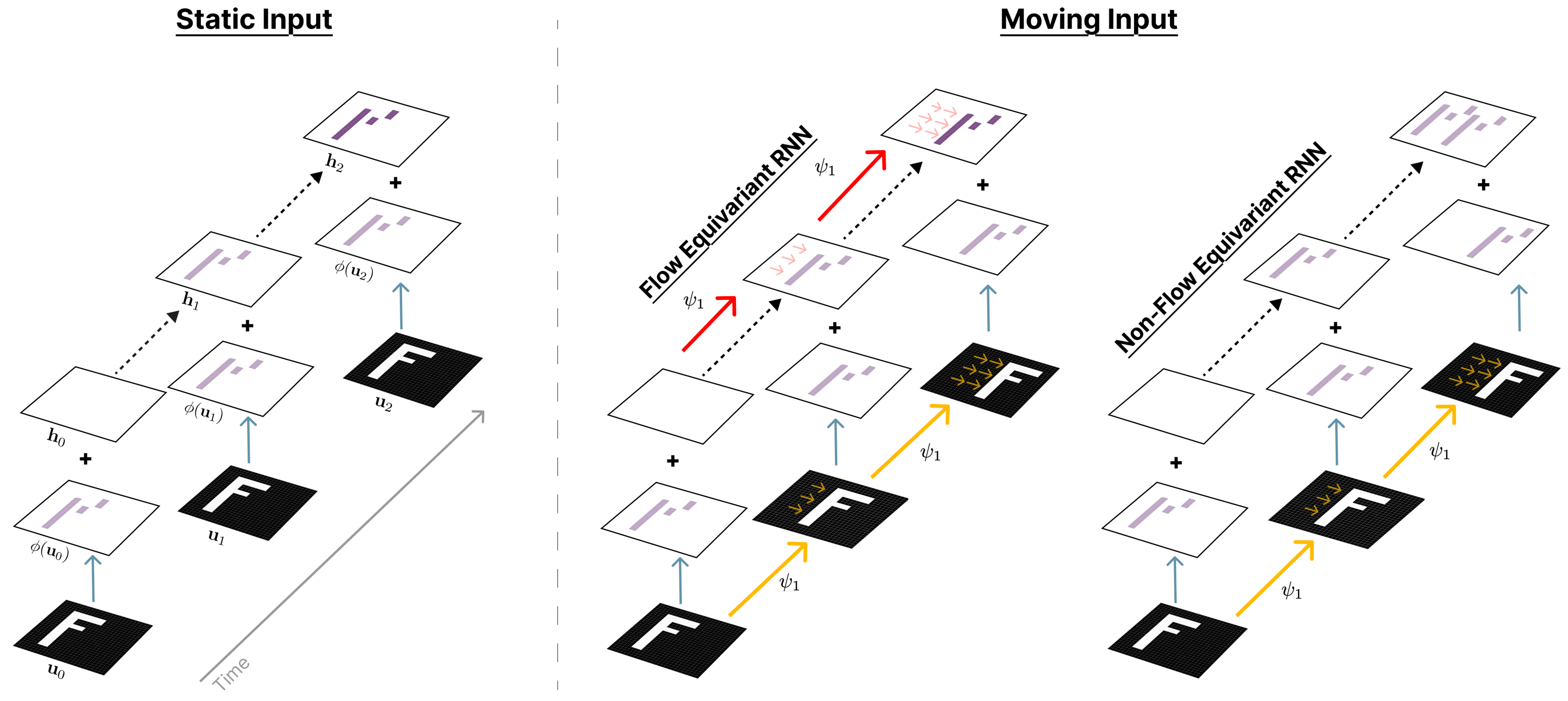 A flow equivariant neural network will process a moving stimulus sequence the same way as it processes a static stimulus sequence, but with the same motion applied to its hidden state. To achieve this property for a specific input flow $\psi^{(\nu)}$, a corresponding flow must preemptively shift the hidden state before the input comes in (denoted by red arrows).
A flow equivariant neural network will process a moving stimulus sequence the same way as it processes a static stimulus sequence, but with the same motion applied to its hidden state. To achieve this property for a specific input flow $\psi^{(\nu)}$, a corresponding flow must preemptively shift the hidden state before the input comes in (denoted by red arrows).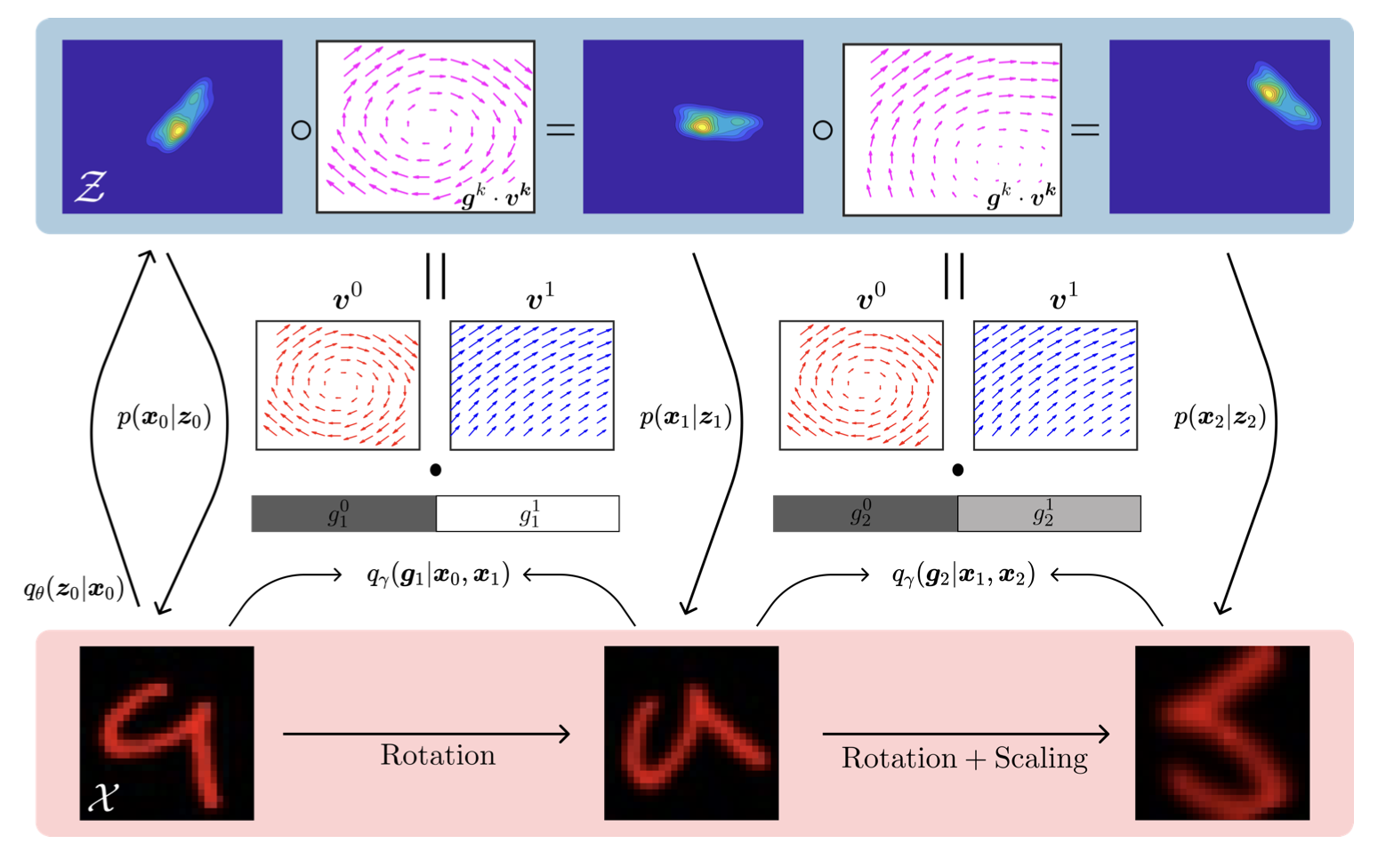 We learn representations from sequence data by factorizing latent transformations into sparse flow components, yielding disentangled transformation primitives and approximately equivariant structure.
We learn representations from sequence data by factorizing latent transformations into sparse flow components, yielding disentangled transformation primitives and approximately equivariant structure.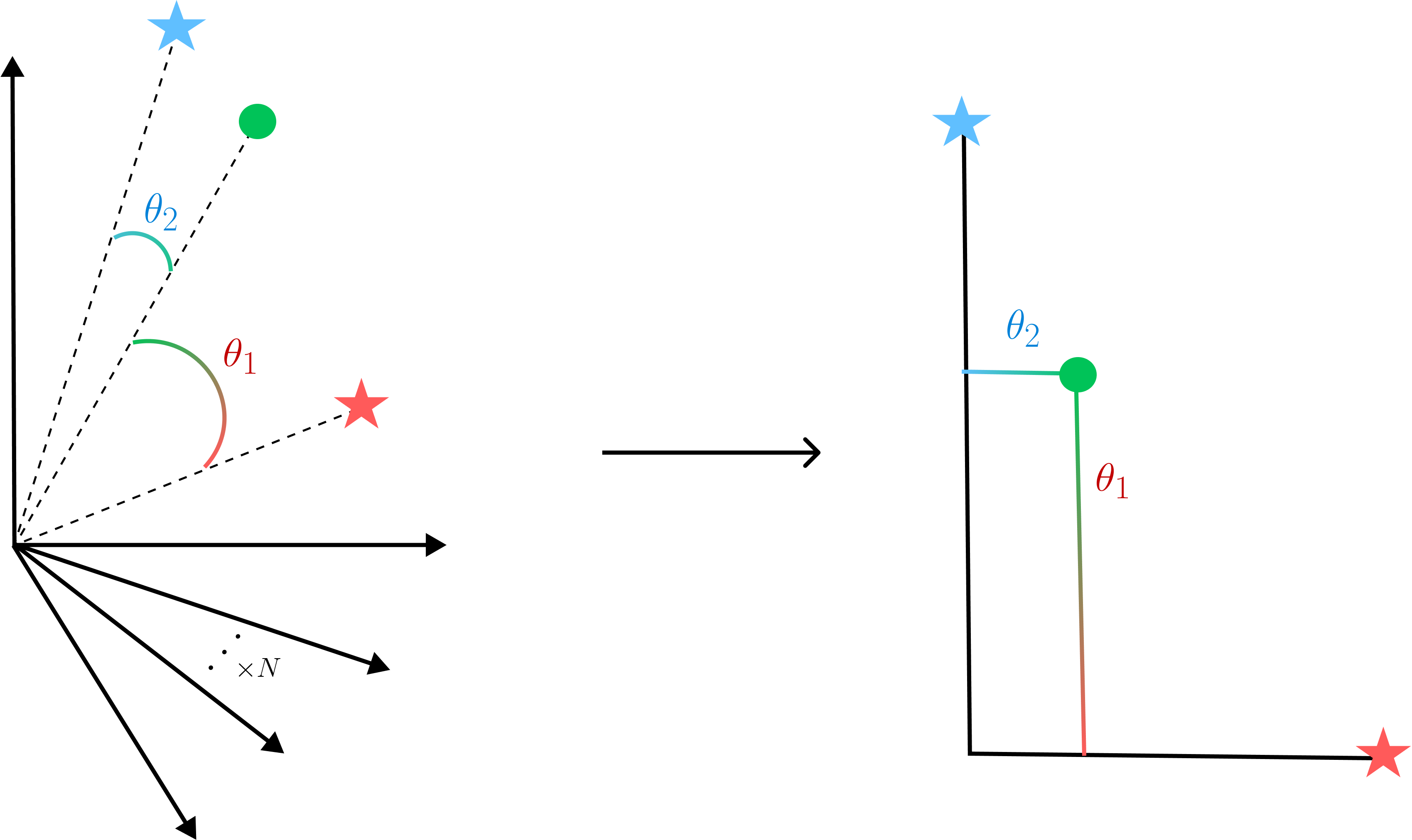 Relative Representations are a method for mapping points (such as the green circle) from a high dimensional space (left) to a lower dimensional space (right), by represeniting it in a new coordinate system relative to a select set of anchor points (red and blue star). In this work we apply such an idea of relative representations to model-brain mappings and show that it improves interpretability and computational efficiency – surprisingly model-brain RSA scores are roughly consistent even with as few as 10 randomly selected anchor points (10 dimensions) compared to the original 1000’s of dimensions.
Relative Representations are a method for mapping points (such as the green circle) from a high dimensional space (left) to a lower dimensional space (right), by represeniting it in a new coordinate system relative to a select set of anchor points (red and blue star). In this work we apply such an idea of relative representations to model-brain mappings and show that it improves interpretability and computational efficiency – surprisingly model-brain RSA scores are roughly consistent even with as few as 10 randomly selected anchor points (10 dimensions) compared to the original 1000’s of dimensions.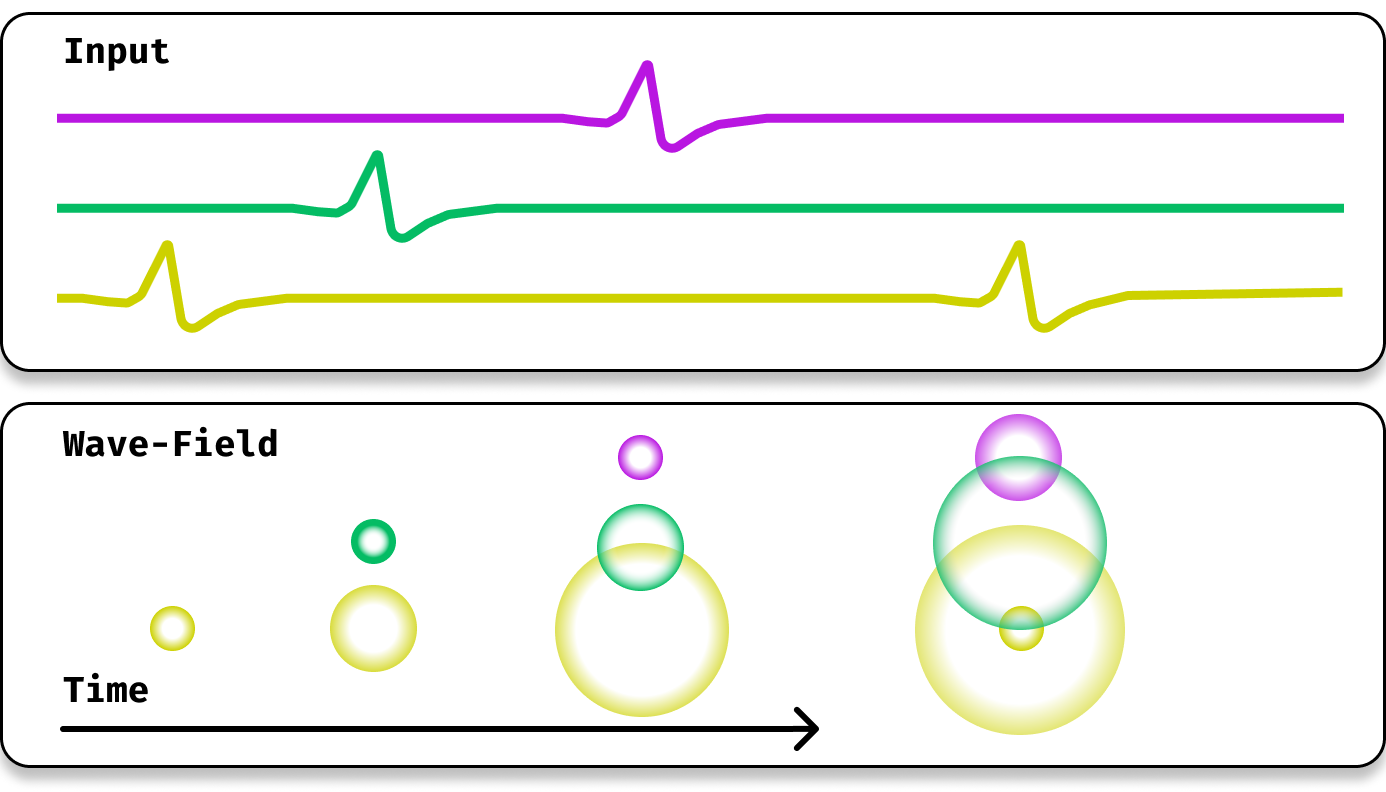 Illustration of three input signals (top) and a corresponding wave-field with induced traveling waves (bottom). From an instantaneous snapshot of the wave-field at each timestep we are able decode both the time of onset and input channel of each input spike. Furthermore, subsequent spikes in the same channel do not overwrite one-another.
Illustration of three input signals (top) and a corresponding wave-field with induced traveling waves (bottom). From an instantaneous snapshot of the wave-field at each timestep we are able decode both the time of onset and input channel of each input spike. Furthermore, subsequent spikes in the same channel do not overwrite one-another. My PhD Thesis, studying the inductive biases that enable the efficiency and generalization capability of natural intelligence, yet unmatched by artificial intelligence.
My PhD Thesis, studying the inductive biases that enable the efficiency and generalization capability of natural intelligence, yet unmatched by artificial intelligence.