Overview of Homomorphic-SSL (left) and its relation to traditional Augmentation-based SSL (right). Positive pairs extracted from the lifted dimension (θ) of a rotation equivariant network (G-conv) are equivalent to pairs extracted from the separate representations of two rotated images
Illustration of our flow factorized representation learning: at each point in the latent space we have a distinct set of tangent directions \(\nabla u^k\) which define different transformations we would like to model in the image space. For each path, the latent sample evolves to the target on the potential landscape following dynamic optimal transport.
Visualization of the DUET framework. The backbone \(f\) yields a 2d representation for each transformed image \(f(\tau_g(\mathbf{x}))\) (e.g. \(\tau_g\) is a rotation by \(g\) degrees). The group marginal is obtained as the softmax (sm) of the sum of the rows, and is compared to the prescribed target (red) with our group loss \(L_G\). The content is obtained by summing the columns, and contrasted (\(L_C\)) with the other view through a projection head \(h\). The final representation for downstream tasks is the 2d one, which has been optimized through its marginals.
Comparison of latent traversals found with our method compared with state of the art baselines (WarpedSpace and SeFa). We see prior work tends to conflate multiple semantic concepts simultaneously due to the enforced linearity of the transformations. In our work, the inherently non-linear nature of the potential flow transformations more accurately disentangles semantically separate transformations.
Observed transformation (left), Latent Variable Waves (middle), and Reconstruction (right). We see the Neural Wave Machine learns to encode the observed transformations as traveling waves. In our paper, we show that such coordinated synchronous dynamics ultimately result in improved forecasting ability and efficiency when similarly modeling smooth continutous transformations as input.
Measured orientation selectivity of neurons, as color coded by the bars on the left. We see our LocoRNN’s simulated cortical sheet learns selectivity reminiscent of the orientation columns observed in the Macaque primary visual cortex (source: Principles of Neural Science. E. Kandel, J. Schwartz, T. Jessell, S. Siegelbaum, & A. Hudspeth. 2013.).
Measurement of selectivity of top-layer neurons to images of Faces vs. images of Objects. The baseline pretrained Alexnet model (left) has randomly organized selectivity as expected. We see the Topographic VAE (middle) yeilds spatially dense clusters of neurons selective to images of faces, reminiscent of the ‘face patches’ observed in the primate cortex. The TVAE clusters are seen to be qualitatively similar to those produced by the supervised TDANN model of Lee et al. (2020) (right) without the need for class-labels during training.
We introduce a modification of the Topographic VAE, allowing it to be used in an online manner as a predictive model of the future. We observe that the Predictive Coding TVAE (PCTVAE) is able to learn more coherent sequence transformations (left) when compared with the original Topographic VAE (right).
Overview of the Topographic VAE with shifting temporal coherence. The combined color/rotation transformation in input space \(\tau_g\) becomes encoded as a \(\mathrm{Roll}\) within the equivariant capsule dimension. The model is thus able decode unseen sequence elements by encoding a partial sequence and rolling activations within the capsules. We see this completes a commutative diagram.
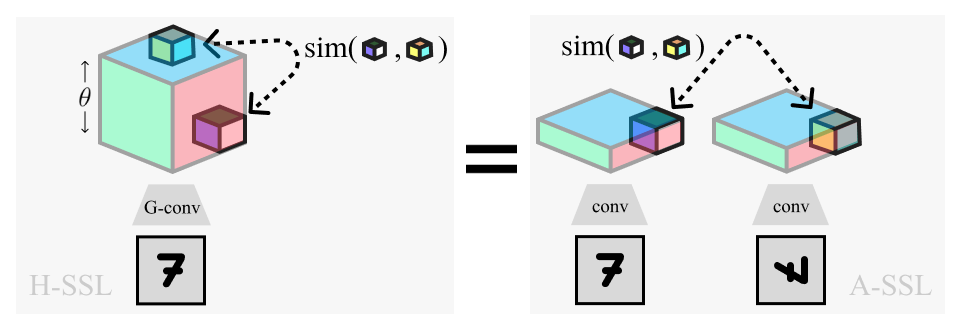 Overview of Homomorphic-SSL (left) and its relation to traditional Augmentation-based SSL (right). Positive pairs extracted from the lifted dimension (θ) of a rotation equivariant network (G-conv) are equivalent to pairs extracted from the separate representations of two rotated images
Overview of Homomorphic-SSL (left) and its relation to traditional Augmentation-based SSL (right). Positive pairs extracted from the lifted dimension (θ) of a rotation equivariant network (G-conv) are equivalent to pairs extracted from the separate representations of two rotated images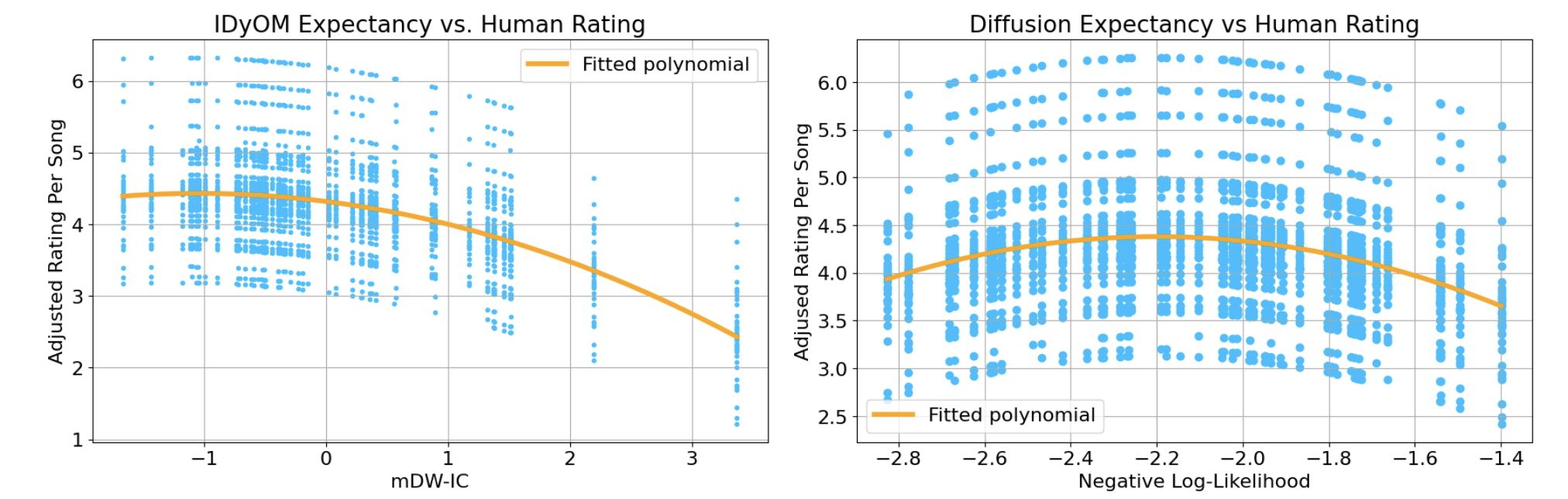 We show the expected ‘inverted U-shaped’ relationship between human song ratings and music likelihood under a modern diffusion model.
We show the expected ‘inverted U-shaped’ relationship between human song ratings and music likelihood under a modern diffusion model.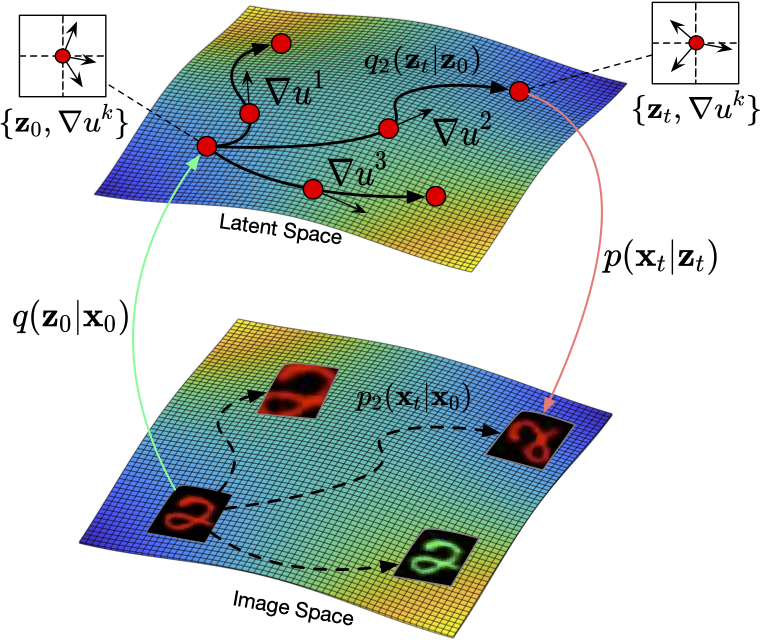 Illustration of our flow factorized representation learning: at each point in the latent space we have a distinct set of tangent directions \(\nabla u^k\) which define different transformations we would like to model in the image space. For each path, the latent sample evolves to the target on the potential landscape following dynamic optimal transport.
Illustration of our flow factorized representation learning: at each point in the latent space we have a distinct set of tangent directions \(\nabla u^k\) which define different transformations we would like to model in the image space. For each path, the latent sample evolves to the target on the potential landscape following dynamic optimal transport.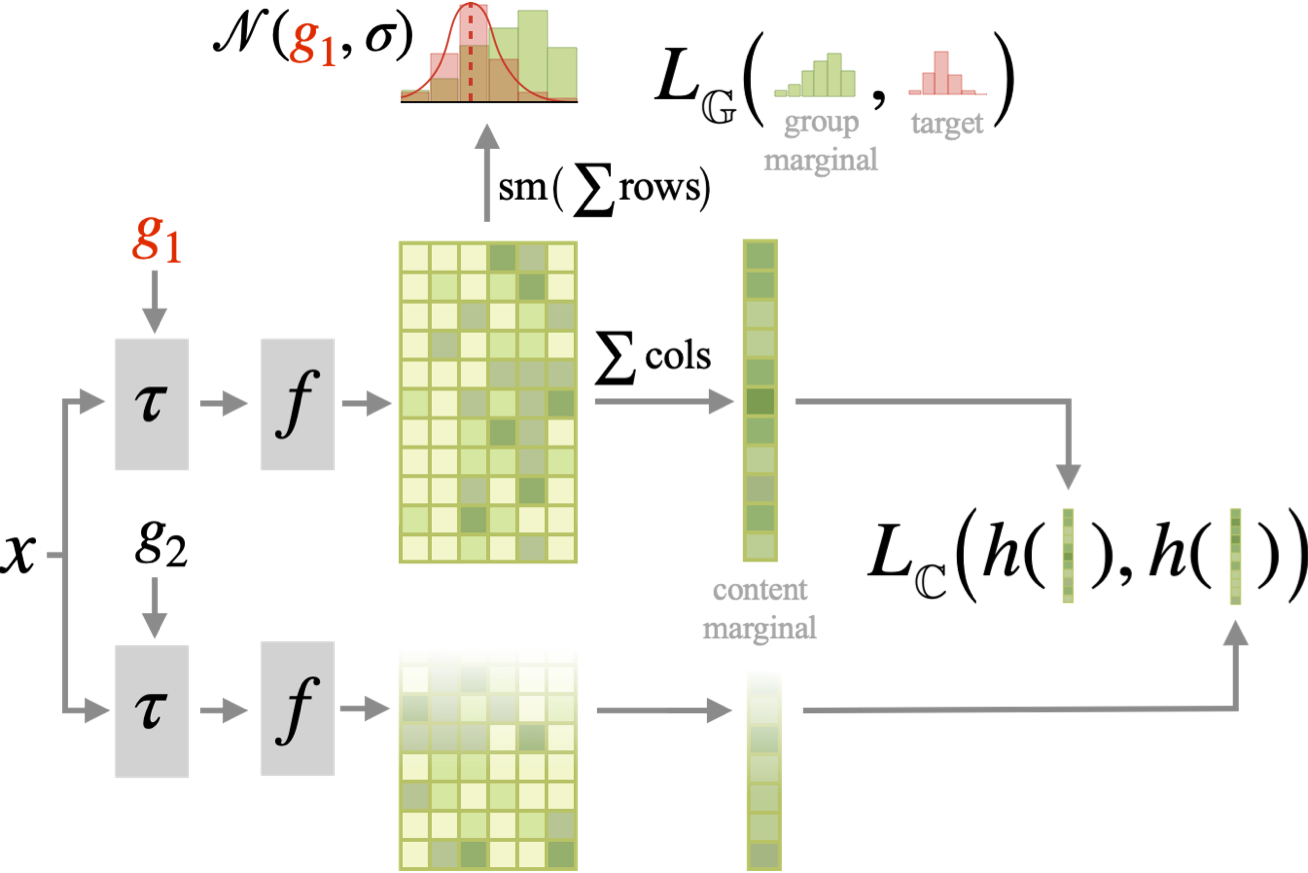 Visualization of the DUET framework. The backbone \(f\) yields a 2d representation for each transformed image \(f(\tau_g(\mathbf{x}))\) (e.g. \(\tau_g\) is a rotation by \(g\) degrees). The group marginal is obtained as the softmax (sm) of the sum of the rows, and is compared to the prescribed target (red) with our group loss \(L_G\). The content is obtained by summing the columns, and contrasted (\(L_C\)) with the other view through a projection head \(h\). The final representation for downstream tasks is the 2d one, which has been optimized through its marginals.
Visualization of the DUET framework. The backbone \(f\) yields a 2d representation for each transformed image \(f(\tau_g(\mathbf{x}))\) (e.g. \(\tau_g\) is a rotation by \(g\) degrees). The group marginal is obtained as the softmax (sm) of the sum of the rows, and is compared to the prescribed target (red) with our group loss \(L_G\). The content is obtained by summing the columns, and contrasted (\(L_C\)) with the other view through a projection head \(h\). The final representation for downstream tasks is the 2d one, which has been optimized through its marginals. Comparison of latent traversals found with our method compared with state of the art baselines (WarpedSpace and SeFa). We see prior work tends to conflate multiple semantic concepts simultaneously due to the enforced linearity of the transformations. In our work, the inherently non-linear nature of the potential flow transformations more accurately disentangles semantically separate transformations.
Comparison of latent traversals found with our method compared with state of the art baselines (WarpedSpace and SeFa). We see prior work tends to conflate multiple semantic concepts simultaneously due to the enforced linearity of the transformations. In our work, the inherently non-linear nature of the potential flow transformations more accurately disentangles semantically separate transformations.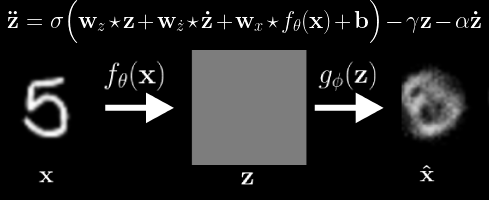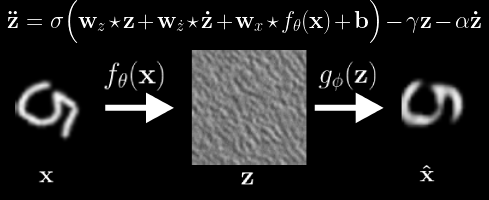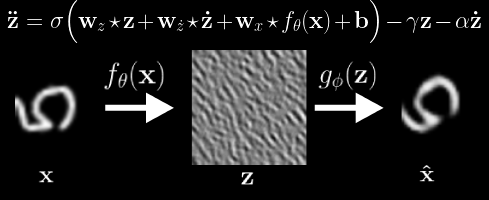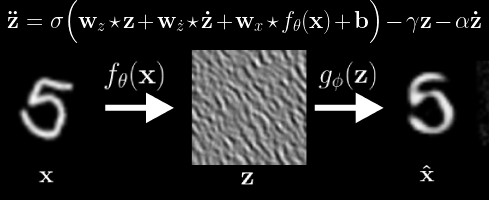 Observed transformation (left), Latent Variable Waves (middle), and Reconstruction (right). We see the Neural Wave Machine learns to encode the observed transformations as traveling waves. In our paper, we show that such coordinated synchronous dynamics ultimately result in improved forecasting ability and efficiency when similarly modeling smooth continutous transformations as input.
Observed transformation (left), Latent Variable Waves (middle), and Reconstruction (right). We see the Neural Wave Machine learns to encode the observed transformations as traveling waves. In our paper, we show that such coordinated synchronous dynamics ultimately result in improved forecasting ability and efficiency when similarly modeling smooth continutous transformations as input.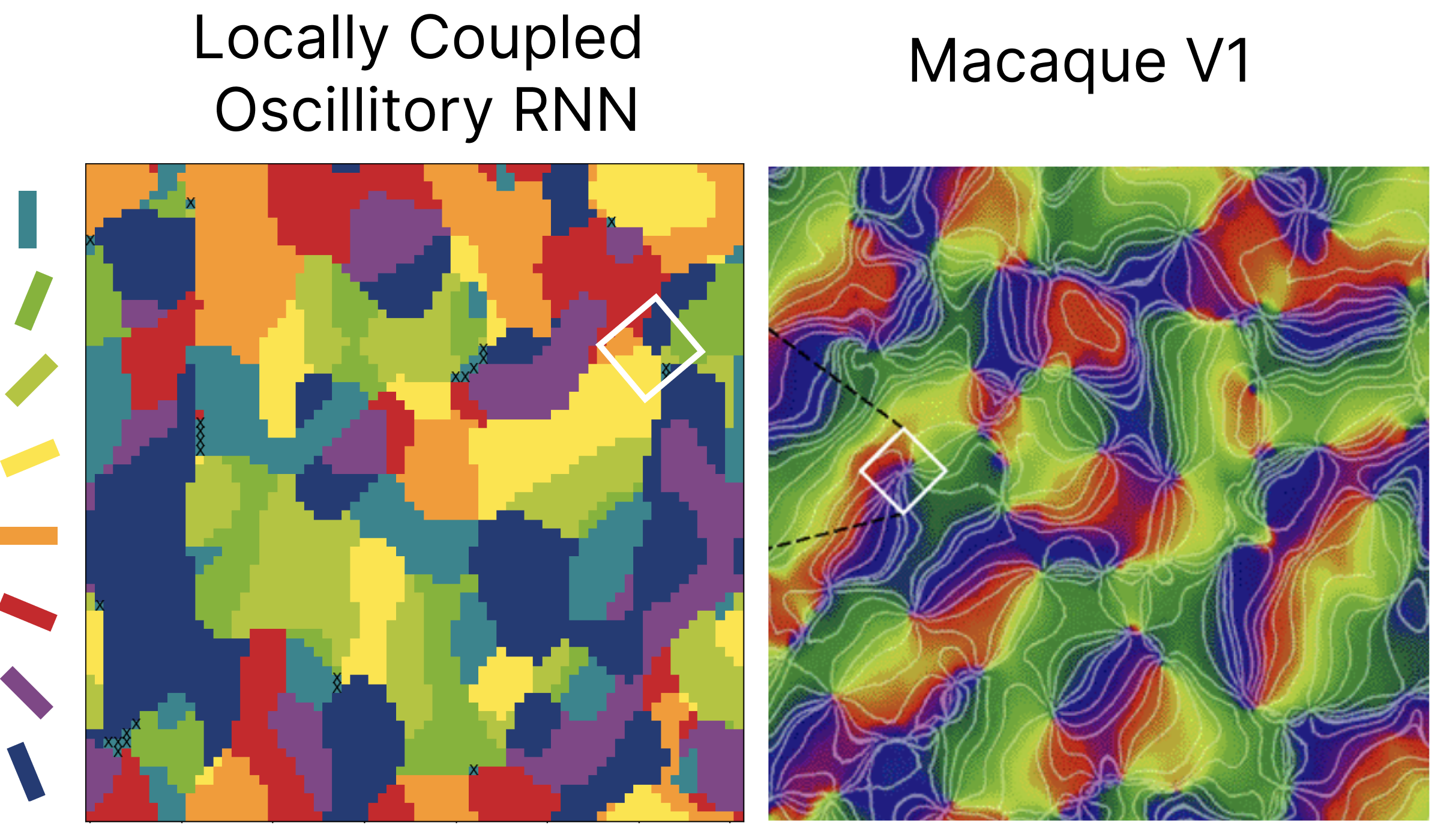 Measured orientation selectivity of neurons, as color coded by the bars on the left. We see our LocoRNN’s simulated cortical sheet learns selectivity reminiscent of the orientation columns observed in the Macaque primary visual cortex (source: Principles of Neural Science. E. Kandel, J. Schwartz, T. Jessell, S. Siegelbaum, & A. Hudspeth. 2013.).
Measured orientation selectivity of neurons, as color coded by the bars on the left. We see our LocoRNN’s simulated cortical sheet learns selectivity reminiscent of the orientation columns observed in the Macaque primary visual cortex (source: Principles of Neural Science. E. Kandel, J. Schwartz, T. Jessell, S. Siegelbaum, & A. Hudspeth. 2013.).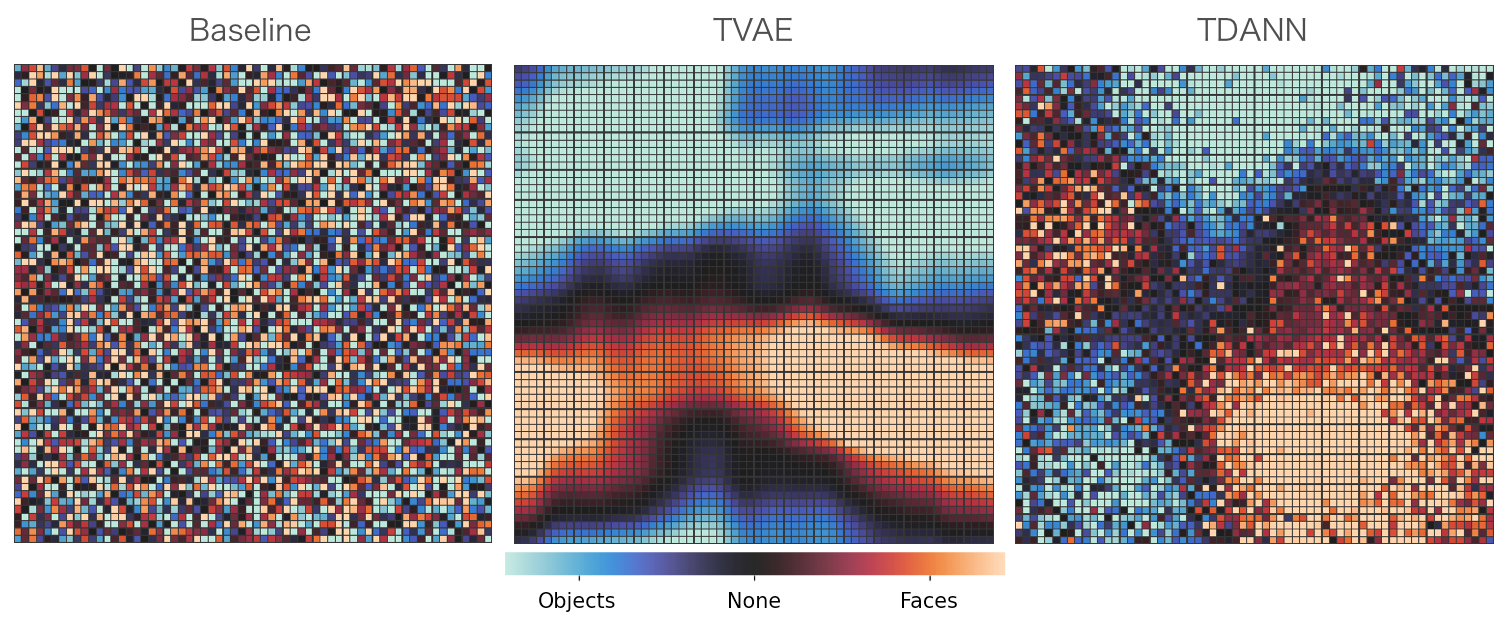 Measurement of selectivity of top-layer neurons to images of Faces vs. images of Objects. The baseline pretrained Alexnet model (left) has randomly organized selectivity as expected. We see the Topographic VAE (middle) yeilds spatially dense clusters of neurons selective to images of faces, reminiscent of the ‘face patches’ observed in the primate cortex. The TVAE clusters are seen to be qualitatively similar to those produced by the supervised TDANN model of Lee et al. (2020) (right) without the need for class-labels during training.
Measurement of selectivity of top-layer neurons to images of Faces vs. images of Objects. The baseline pretrained Alexnet model (left) has randomly organized selectivity as expected. We see the Topographic VAE (middle) yeilds spatially dense clusters of neurons selective to images of faces, reminiscent of the ‘face patches’ observed in the primate cortex. The TVAE clusters are seen to be qualitatively similar to those produced by the supervised TDANN model of Lee et al. (2020) (right) without the need for class-labels during training. We introduce a modification of the Topographic VAE, allowing it to be used in an online manner as a predictive model of the future. We observe that the Predictive Coding TVAE (PCTVAE) is able to learn more coherent sequence transformations (left) when compared with the original Topographic VAE (right).
We introduce a modification of the Topographic VAE, allowing it to be used in an online manner as a predictive model of the future. We observe that the Predictive Coding TVAE (PCTVAE) is able to learn more coherent sequence transformations (left) when compared with the original Topographic VAE (right).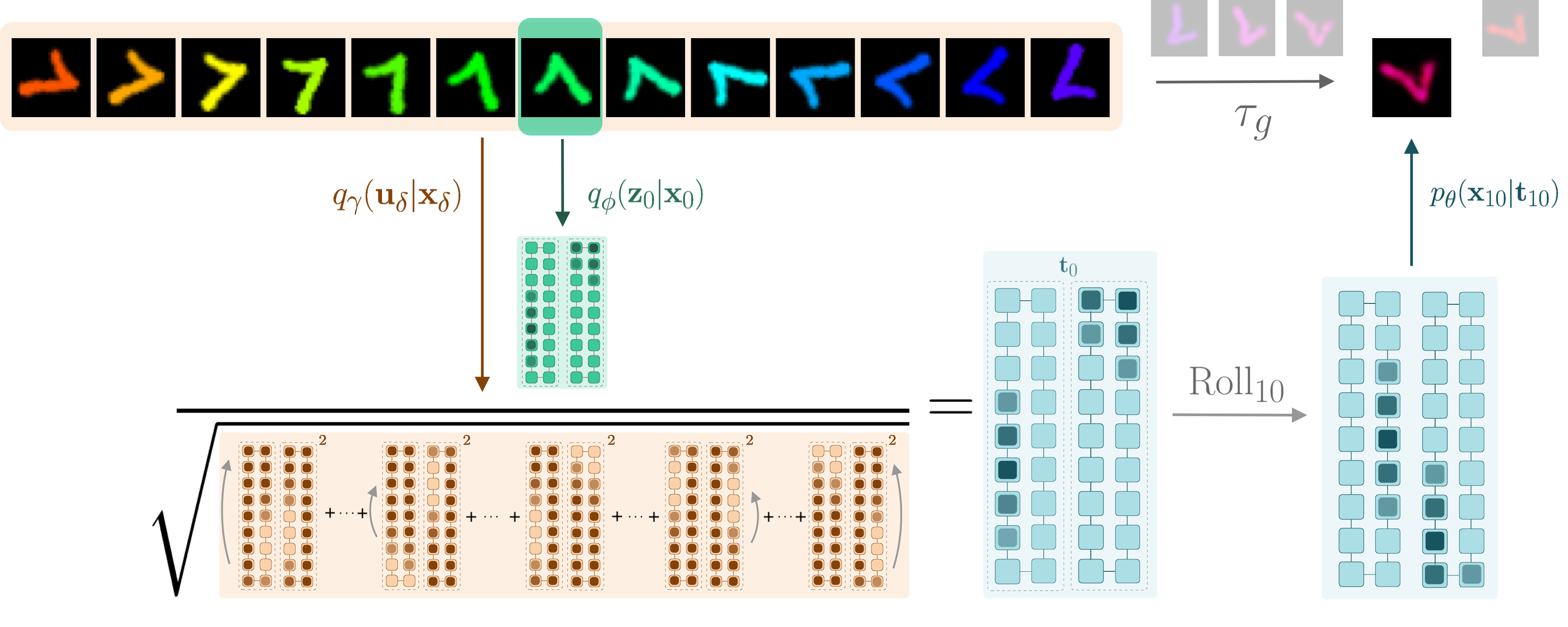 Overview of the Topographic VAE with shifting temporal coherence. The combined color/rotation transformation in input space \(\tau_g\) becomes encoded as a \(\mathrm{Roll}\) within the equivariant capsule dimension. The model is thus able decode unseen sequence elements by encoding a partial sequence and rolling activations within the capsules. We see this completes a commutative diagram.
Overview of the Topographic VAE with shifting temporal coherence. The combined color/rotation transformation in input space \(\tau_g\) becomes encoded as a \(\mathrm{Roll}\) within the equivariant capsule dimension. The model is thus able decode unseen sequence elements by encoding a partial sequence and rolling activations within the capsules. We see this completes a commutative diagram.