Comparison of time series models as a function of missing data (x axis), and class imbalance (three plots). We see that baseline models (GRU & GRU-D with class-reweighting) perform significantly worse than models pre-trained with APC (auto-regressive predictive coding). These results suggest APC as an effective self-supervised learning method for handling missing data and class imbalance simultaneously.
A matrix \(\mathbf{W}\) transforms data from \(\mathbf{X}\) to \(\mathbf{Z}\) space. The matrix \(\mathbf{R}\) is constrained to approximate the inverse of \(\mathbf{W}\) with a reconstruction loss \(||\mathbf{x} - \mathbf{\hat{x}}||^2\). The likelihood of the data is efficiently optimized with respect to both \(\mathbf{W}\) and \(\mathbf{R}\) by approximating the gradient of the log Jacobian determinant with the learned inverse.
A depiction of our gated Long Short-Term Memory cell augmented with an associative memory matrix A which is updated via the outer-product of the gated LSTM cell’s output.
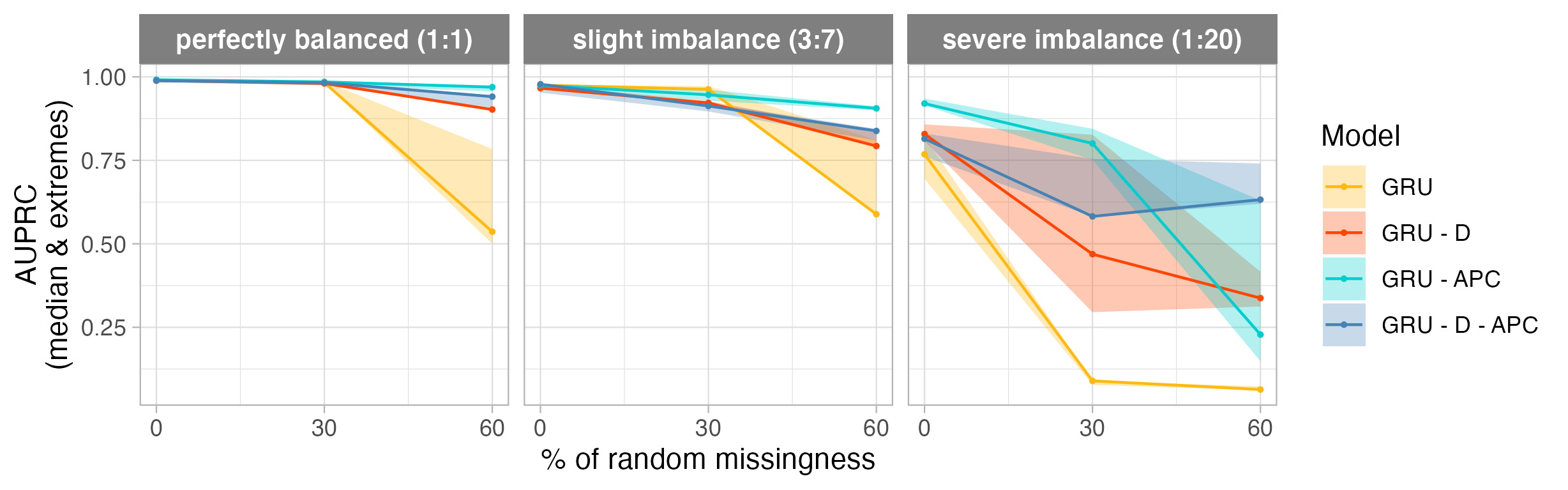 Comparison of time series models as a function of missing data (x axis), and class imbalance (three plots). We see that baseline models (GRU & GRU-D with class-reweighting) perform significantly worse than models pre-trained with APC (auto-regressive predictive coding). These results suggest APC as an effective self-supervised learning method for handling missing data and class imbalance simultaneously.
Comparison of time series models as a function of missing data (x axis), and class imbalance (three plots). We see that baseline models (GRU & GRU-D with class-reweighting) perform significantly worse than models pre-trained with APC (auto-regressive predictive coding). These results suggest APC as an effective self-supervised learning method for handling missing data and class imbalance simultaneously.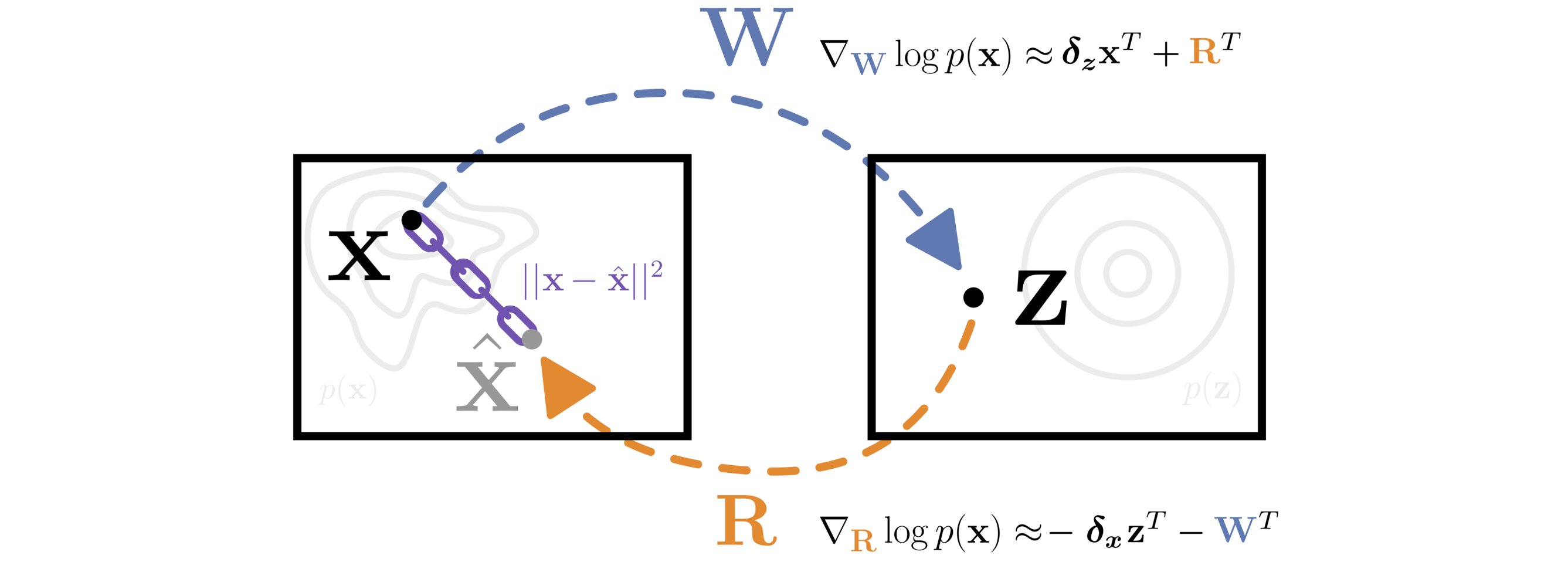 A matrix \(\mathbf{W}\) transforms data from \(\mathbf{X}\) to \(\mathbf{Z}\) space. The matrix \(\mathbf{R}\) is constrained to approximate the inverse of \(\mathbf{W}\) with a reconstruction loss \(||\mathbf{x} - \mathbf{\hat{x}}||^2\). The likelihood of the data is efficiently optimized with respect to both \(\mathbf{W}\) and \(\mathbf{R}\) by approximating the gradient of the log Jacobian determinant with the learned inverse.
A matrix \(\mathbf{W}\) transforms data from \(\mathbf{X}\) to \(\mathbf{Z}\) space. The matrix \(\mathbf{R}\) is constrained to approximate the inverse of \(\mathbf{W}\) with a reconstruction loss \(||\mathbf{x} - \mathbf{\hat{x}}||^2\). The likelihood of the data is efficiently optimized with respect to both \(\mathbf{W}\) and \(\mathbf{R}\) by approximating the gradient of the log Jacobian determinant with the learned inverse.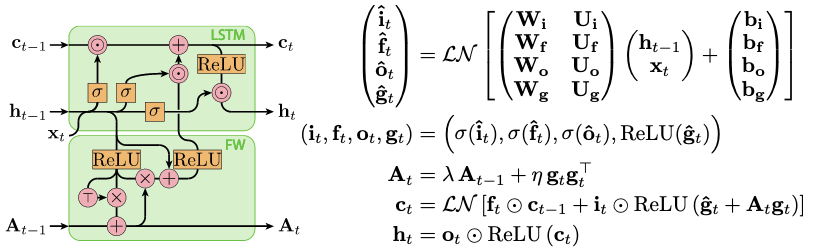 A depiction of our gated Long Short-Term Memory cell augmented with an associative memory matrix A which is updated via the outer-product of the gated LSTM cell’s output.
A depiction of our gated Long Short-Term Memory cell augmented with an associative memory matrix A which is updated via the outer-product of the gated LSTM cell’s output.